AI Agents vs Runners
Private AI coding tools help individuals. Forkline runners make AI work visible company infrastructure: tickets, repos, CI, and review.
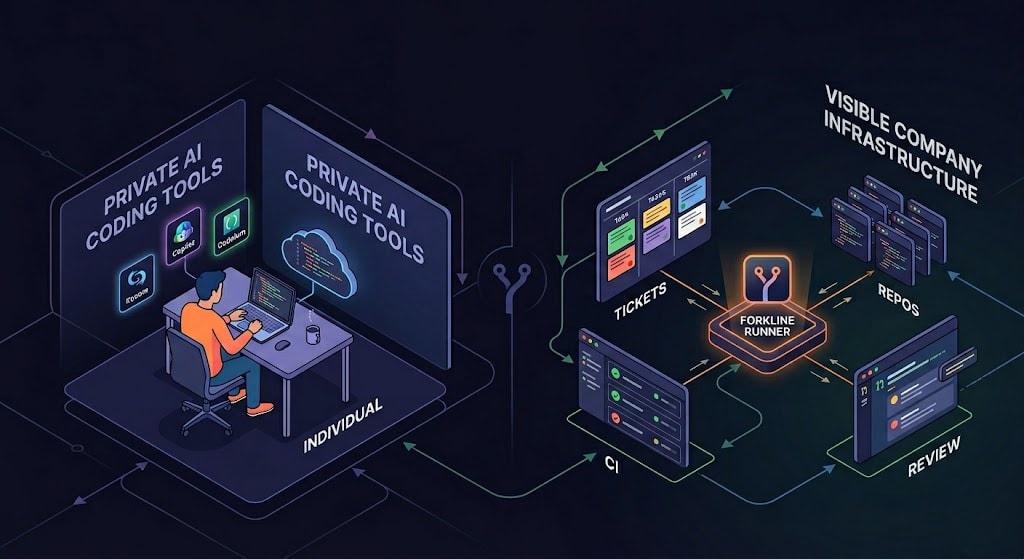
Most AI coding tools still assume one developer, one prompt, and one private session. That works for individual assistance. Engineering teams need something different: AI work that is assigned, executed, reviewed, and measured inside the systems the company already trusts.
Most AI coding tools still assume the same basic shape: one developer opens a local tool, asks for help, gets code back, and decides what to do next.
That workflow is useful. It helps when the bottleneck is drafting, exploring an API, explaining a file, or turning a rough idea into a first implementation. GitHub Copilot, Cursor, and Claude cloud agents all solve real problems for individual developers.
But companies do not run engineering work through private prompts. They run it through shared systems: tickets, repos, branches, pull requests, CI, review, and release processes. That difference matters when a team is looking for a GitHub Copilot alternative for repo execution or a Claude alternative for visible repo automation.
If coding agents are going to become part of an engineering team, they need to stop behaving only like private developer tools. They need to behave like visible runners in the company workflow.
The private-agent model
The private-agent model is simple:
- A developer gives the agent context.
- The agent produces code or advice.
- The developer decides what to copy, change, commit, or discard.
That model keeps control close to the person using the tool. It also keeps most of the work hidden from the rest of the company until the developer turns it into normal engineering artifacts.
For individual assistance, that is fine. For company workflow automation, it is not enough.
The company still needs to answer basic questions:
- What work was assigned?
- What changed?
- Why did it change?
- Did CI pass?
- Who reviewed it?
- What should happen next?
Those answers should not live only in a chat transcript or an IDE session.
The company-visible runner model
The runner model starts from the company workflow instead of the private prompt.
The runner is not replacing the team. It is adding execution capacity inside the systems the team already uses.
That means the output should be reviewable as engineering work, not just readable as generated text. The branch matters. The PR matters. The logs matter. The CI result matters. The human decision still matters.
This is the reason Forkline is positioned as AI runners for engineering teams.
Forkline is intentionally scoped to Git-native workflows today: GitHub, GitLab, Gitea, and Forgejo. Jira and Linear are coming soon. Deeper B2B support, enterprise features, advanced compliance, and broader cross-system orchestration are roadmap items, not claims we want to overstate.
That boundary matters because company workflow automation depends on trust.
Different layers solve different problems
GitHub Copilot and Claude cloud agents both offer a cloud agentic execution layer, not just local code completion. That is useful, but it also bundles workflow automation with the provider’s model list, seat model, credits, or token economics.
Forkline is designed around a different product layer: repo automation through configurable runner execution.
Private prompt
Context lives in one developer session until someone translates it into the team workflow.
Shared assignment
Tickets, repo state, and CI signals define what the runner is allowed to do.
Advice or generated code
The useful parts still need to become commits, summaries, and validation evidence.
Engineering artifact
Branches, PRs, logs, and test results are produced where reviewers already work.
Operator-dependent trust
The company often sees only the final result, not the execution path.
Visible evidence
Reviewers can inspect the task, changes, runner notes, and CI outcome.
Bundled product layer
Model, UI, and billing often arrive as one AI product package.
Separated execution layer
BYOM keeps model selection flexible while Forkline bills for runner execution hours.
The distinction is not that one product is better in every case. It is that teams should be clear about the execution layer they are buying:
- GitHub Copilot and Claude both provide cloud agentic execution tied to their supported model lists and provider billing models.
- Claude is especially strong for model-native automation routines, but the execution surface is still the model provider itself.
- Forkline sits in the repo runner layer: it publishes work into the company’s shared Git workflow, lets teams bring their own models, exposes the execution trail, and bills for runner hours.
If the team needs a smarter editor companion, a private coding agent may be enough. If the team needs reviewable execution capacity for tickets, repos, CI, and review, the runner layer becomes more important.
BYOM keeps model choice separate from execution
If companies are going to use AI runners continuously, model choice matters.
Forkline is BYOM: bring your own models and API keys. Teams can connect GitHub Copilot, OpenAI, Anthropic via API key, local models, OpenAI-compatible providers, and other providers through API support where available. That keeps Forkline focused on execution instead of forcing another bundled model subscription.
This matters for three reasons.
Together, those choices make continuous runner usage easier to operate as everyday engineering infrastructure rather than an occasional demo budget.
Infrastructure economics, not another premium seat
AI runners only become useful when companies can afford to run them continuously.
If every useful automation requires another expensive seat, teams will ration it. They will save it for demos, special cases, or a few developers. That does not create a software factory. It creates a premium tool budget.
Forkline starts at $2.50/month during the 75% launch promotion. The long-term point is not just that the launch price is low. The point is that AI execution capacity should have infrastructure economics: predictable enough for small teams to try, repeat, measure, and eventually scale.
Comparative pricing claims need careful benchmarking, so pricing should stay transparent instead of hand-wavy. Forkline’s direction is explicit: offer the best runner execution price in the industry, keep model costs separate through BYOM, and make continuous AI execution practical for teams.
Tickets as the assignment layer
Tickets are not just project-management overhead. In a company, tickets are the assignment layer for ticket-driven AI automation.
They explain what needs to happen, who asked for it, how it should be scoped, and where the result should be discussed. If AI runners are going to do engineering work for a team, tickets are the right place for that work to begin.
The exact system can vary. Forkline currently supports Git-native workflows through GitHub, GitLab, Gitea, and Forgejo. Jira and Linear are coming soon. The broader point is that AI execution should connect to the workflow the company already uses, not disappear into a private tool.
Artifacts and trust
AI work is easier to trust when it leaves artifacts.
A useful runner should leave enough evidence for a reviewer to understand what happened:
- the task or issue that started the work
- the branch and commits it created
- the PR summary
- execution logs or runner notes
- CI results where applicable
- the human review decision
Forkline’s strongest public proof today is a CI recovery flow on promrail. A Renovate PR broke CI by using a non-existent floating action tag. A Forkline runner identified the missing tag, also found a deprecated action, pushed two fix commits, and CI passed again (see the PR).
That example does not prove every future workflow. It does show the kind of artifact trail that matters: failing signal, runner diagnosis, commits, PR, and CI result.
The category shift
The category shift is not “AI can write code.” That is already obvious.
The shift is that AI work needs to become visible company work.
For a developer, a private coding agent can be enough. For a company, the useful system is different: tickets assign work, runners execute, repos hold artifacts, CI checks the result, humans review, and the workflow gets feedback.
That is the software factory direction Forkline is building toward.
Conclusion
Private coding agents help individuals work faster. Company-visible AI runners help teams add reviewable execution capacity.
That is the difference Forkline is trying to make concrete:
- runners take bounded engineering work from tickets
- work lands as branches, PRs, logs, and CI evidence
- teams bring their own models and keep billing separate
- humans keep the final review gate
- pricing makes continuous runner usage practical
The goal is not hidden AI output. The goal is engineering work the company can see, review, and build feedback loops around.