Fix failing GitHub Actions
How AI runners can turn a red GitHub Actions run into a reviewable fix without hiding the work.
A failed workflow is not just a red icon. It blocks merges, interrupts feature work, and leaves someone reading logs instead of moving the product forward.
When GitHub Actions goes red, the fix usually starts the same way: open the failed job, scroll through a long log, find the first real error, reproduce enough of the failure locally, patch the workflow or dependency, push again, and wait.
That loop is normal engineering work. It is also a good place for an AI runner, as long as the runner is treated like execution infrastructure instead of a private chat window.
The useful outcome is not “AI looked at CI.” The useful outcome is a branch, commits, a pull request, and a passing check that the team can review.
What you should take away
- Failed GitHub Actions runs are often bounded, high-signal tasks.
- AI runners are most useful when they work from logs, repository state, and a narrow repair goal.
- The fix should land as normal engineering artifacts: branch, commits, PR, CI result, and human review.
- Forkline’s strongest public proof today is a real CI recovery PR on promrail, not a synthetic demo.
Why CI failures are a good runner task
Not every engineering task should be handed to an automated runner. CI repair is different because the failure usually comes with a lot of useful structure.
The runner can start from a concrete signal:
- the failed workflow
- the failed job and step
- the error output
- the branch or pull request that introduced the failure
- the repository files that define the workflow
That does not make the task trivial. GitHub Actions failures can come from missing tags, changed tool behavior, broken package resolution, permission differences, expired caches, or environment drift. But the task is still bounded: make this workflow pass again, and show the evidence.
Read the signal, inspect the repo, make the smallest plausible fix.
That boundary matters. A good CI repair runner is not trying to redesign the repository. It is trying to explain the failure, make the smallest plausible fix, and put the result back into the team’s review flow.
The manual loop is expensive
For a small team, a red workflow has an immediate cost.
Merges slow down. Review queues back up. Someone who was working on product code is now reading infrastructure logs. If the failure came from a dependency update or a third-party action, the person debugging it may not even have useful local context.
The frustrating part is that many CI failures are not conceptually hard. They are tedious, high-context, and interrupt-driven.
That is exactly the kind of work where an AI runner can help, provided it leaves enough evidence for a human to trust the result.
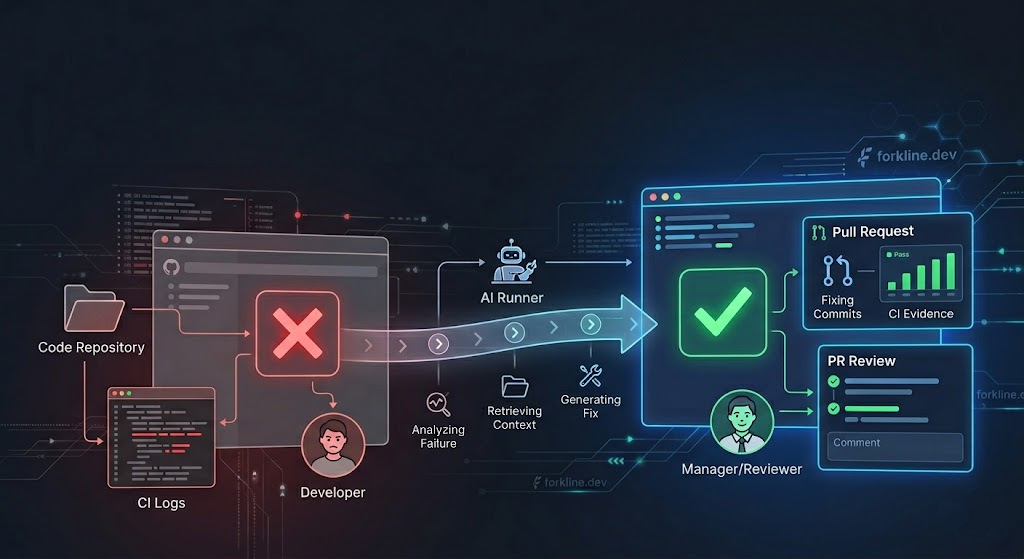
How a runner should repair a failed workflow
A useful CI repair flow has a simple shape.
- Read the failing signal. Start with the failed GitHub Actions run, the job log, and the workflow definition.
- Narrow the task. Identify whether the failure is likely in the workflow, dependency graph, tool version, test code, or environment setup.
- Create a branch. Keep the repair isolated instead of pushing directly to the failing branch.
- Make the smallest fix. Prefer a targeted workflow or dependency change over broad rewrites.
- Open a pull request. Explain the diagnosis, the change, and the evidence.
- Wait for CI. The runner output is not complete until the check result is visible.
- Leave the final gate to a human. Passing CI is evidence, not permission to merge by itself.
That is the difference between helpful automation and a black box. The runner does not need to be trusted because it sounds confident. It needs to be trusted because the work is visible.
What this looks like in practice
Forkline’s current public proof is a CI recovery flow on promrail.
A Renovate pull request broke CI by using a non-existent floating action tag. A Forkline runner inspected the failure, identified the missing tag, also noticed a deprecated action, and pushed two fix commits. The pull request then had the normal evidence trail: commits, reviewable diff, and a passing CI result.
You can inspect the artifact directly: promrail CI recovery PR.
That example does not prove every future CI repair case. It does show the operating model Forkline is built around:
- the failure is real
- the runner work is visible
- the fix is reviewable
- CI verifies the result
- humans keep the merge decision
That is the standard AI runner work should meet.
Where Forkline fits
Forkline provides AI runners for engineering teams. For CI repair, that means the runner works inside the Git workflow instead of producing advice that someone has to copy from a chat transcript.
The important product choices are practical:
- Git-native execution for repositories and pull requests
- BYOM support so teams can bring their own model providers and API keys
- runner-hour billing instead of bundled model inference
- reviewable output through branches, commits, PRs, logs, and CI checks
Today, Forkline is intentionally focused on GitHub, GitLab, Gitea, and Forgejo workflows. That scope is enough for many CI repair tasks, and it keeps the claim grounded: runners should fix bounded repository problems and leave normal engineering artifacts behind.
How to start safely
The safest way to introduce AI CI repair is not to let it touch everything on day one.
Start with repositories where the team can evaluate the output quickly. Limit the runner to creating branches and pull requests. Require human review before merge. Track whether the runner reduced time-to-diagnosis, whether the fixes were small, and whether reviewers trusted the explanation.
Good operating rules are simple:
Silent automation
A bot changes CI without a clear review surface.
Reviewable PR
Every fix lands as commits, summary, and diff.
Broad rewrite
The repair drifts from CI recovery into unrelated cleanup.
Small patch
The runner changes only what the failure justifies.
Confidence without proof
A plausible explanation is treated as success.
CI evidence
The check result stays attached to the work.
Auto-merge pressure
Passing CI becomes permission to ship unattended.
Human gate
A reviewer decides whether the fix belongs.
- let runners propose fixes, not merge them silently
- prefer small, reversible changes
- require the PR description to explain the failure and the fix
- keep logs and CI results attached to the workflow
- expand automation only after the team sees repeated value
Those rules keep the runner useful without pretending CI repair should become unattended production change management.
The bottom line
Fixing failing GitHub Actions is not just a search problem or a model benchmark. It is an engineering workflow problem.
The runner needs the failed signal, repository context, a bounded repair goal, and a place to publish the result. The team needs a branch, commits, a PR, CI evidence, and the final review gate.
That is the model Forkline is building toward: AI runners that turn broken CI into reviewable engineering work, not hidden AI output.